From a research idea
to a polished paper.
MAARS is a multi-agent system that takes a vague idea — or a Kaggle competition URL — and autonomously runs the full research loop: literature survey, task decomposition, sandboxed experiments, paper drafting, and peer review.
Ideas are just the start.
The paper is the hard part.
Between a one-sentence idea and a finished research artifact lies a long tail of dirty work: scoping, literature surveys, experiment design, reproducible code, error recovery, writing, revising. MAARS puts an agent-orchestrated loop around that tail — and runs it end to end.
Three stages.
One coherent loop.
Each stage has a stable I/O boundary: a runtime orchestrates control flow and persistence, while agents do the open-ended work.
Explorer drafts a proposal from the user's raw idea. Critic reviews it within a declared scope, surfacing gaps and ambiguities. They iterate until zero issues remain.
The core engine. A strategy decomposes the proposal into atomic tasks, which execute in Docker sandboxes with parallel scheduling. Outputs are verified, then evaluated — loops with strategy updates when gaps exist.
Writer reads all research outputs and drafts a complete paper. Reviewer critiques and drives revisions — same IterationState pattern as Refine. A final Polish sub-step runs a single-pass LLM refinement and appends a deterministic metadata appendix (tokens, timings, scores).
if · for · while, scheduling, retries, termination → runtime. Search, coding, reasoning → agent.
Primary drafts → Reviewer returns {issues, resolved, pass} → Primary revises. Loops until pass=true or the iteration cap.
State lives on disk — JSON + Markdown under results/{session}/. SSE is notification only; the UI reads canonical data from the session DB.
System design.
Clear boundaries, concrete state.
The important split is simple: Python owns control flow and persistence; agents do the open-ended work inside bounded stages.
Every run is a directory.
State is just files. No hidden database, no vector store. You can cd into any session and read exactly what each agent said — drafts, critiques, plan trees, execution logs, polished paper. Reproducible by construction.
results/{session}/
├── idea.md # user input
├── proposals/ critiques/ # Refine: rounds
├── refined_idea.md # Refine: final
├── calibration.md # Research: calibration
├── strategy/ plan_tree.json # Research: strategy · plan
├── plan_list.json # Research: flat task list
├── tasks/ artifacts/ # code · figures · data
├── evaluations/ # Research: eval rounds
├── results_summary.{json,md} # Research: summary
├── drafts/ reviews/ # Write: rounds
├── paper.md # Write: draft
├── paper_polished.md # Write: polished (sub-step)
├── meta.json # metadata (tokens, score)
├── log.jsonl # SSE stream log
├── execution_log.jsonl # Docker exec log
└── reproduce/ # Dockerfile · run.shImplementation choices.
Simple runtime, bounded execution.
The stack is intentionally plain: keep orchestration legible, keep execution isolated, and keep state inspectable on disk.
Runtime, API server, SSE broadcast, session DB.
Multi-agent framework; per-stage model override; native Google Search.
Isolated Python exec with CPU/RAM/GPU quotas, network toggle, timeouts.
Streaming log viewer + right-panel state dashboard reading from DB.
Literature survey, web search, competition data, paper parsing — wired into agents.
JSON & Markdown on disk. No cloud, no migrations. grep-friendly.
Every session emits a reproduce bundle — rerun any experiment from scratch.
Real runs.
Real papers.
Two end-to-end runs from the repo's showcase/ folder — each one producing code, figures, a polished paper, and a reproduce bundle.
Lorenz attractor — 4 figures that tell the chaos story
A one-line prompt: solve the Lorenz system with RK45 and produce 4 chaos figures. Out comes a full paper — derivations, code, and the plots below.
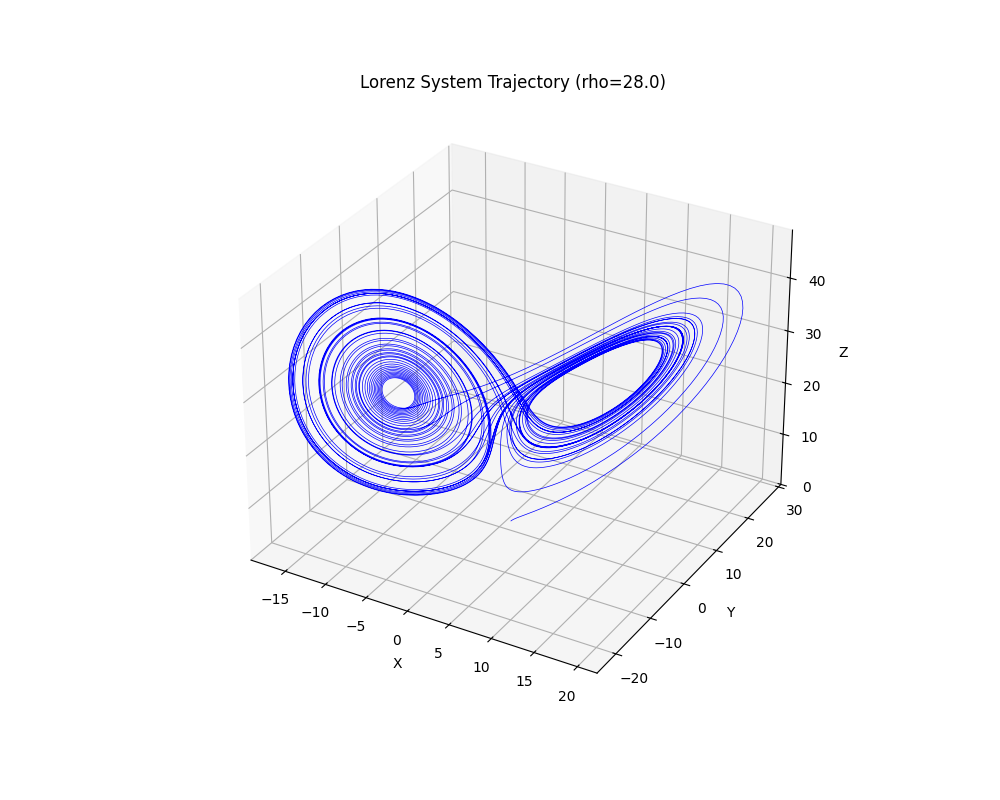
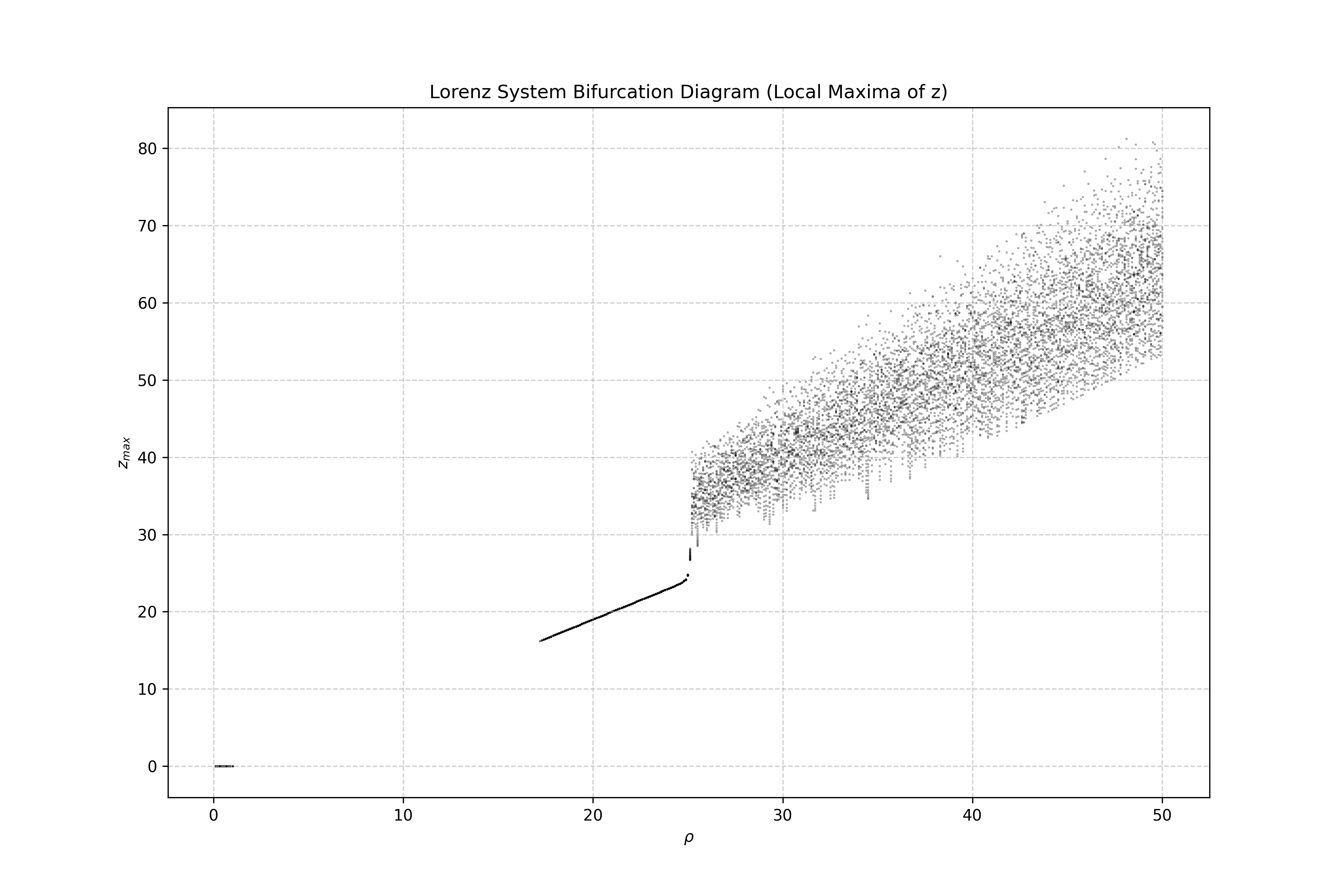
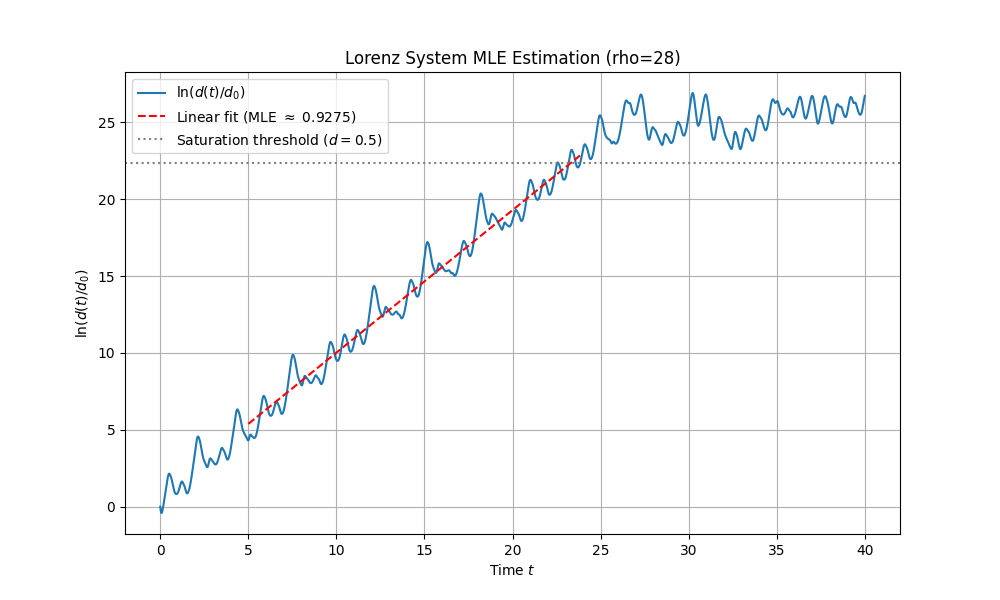
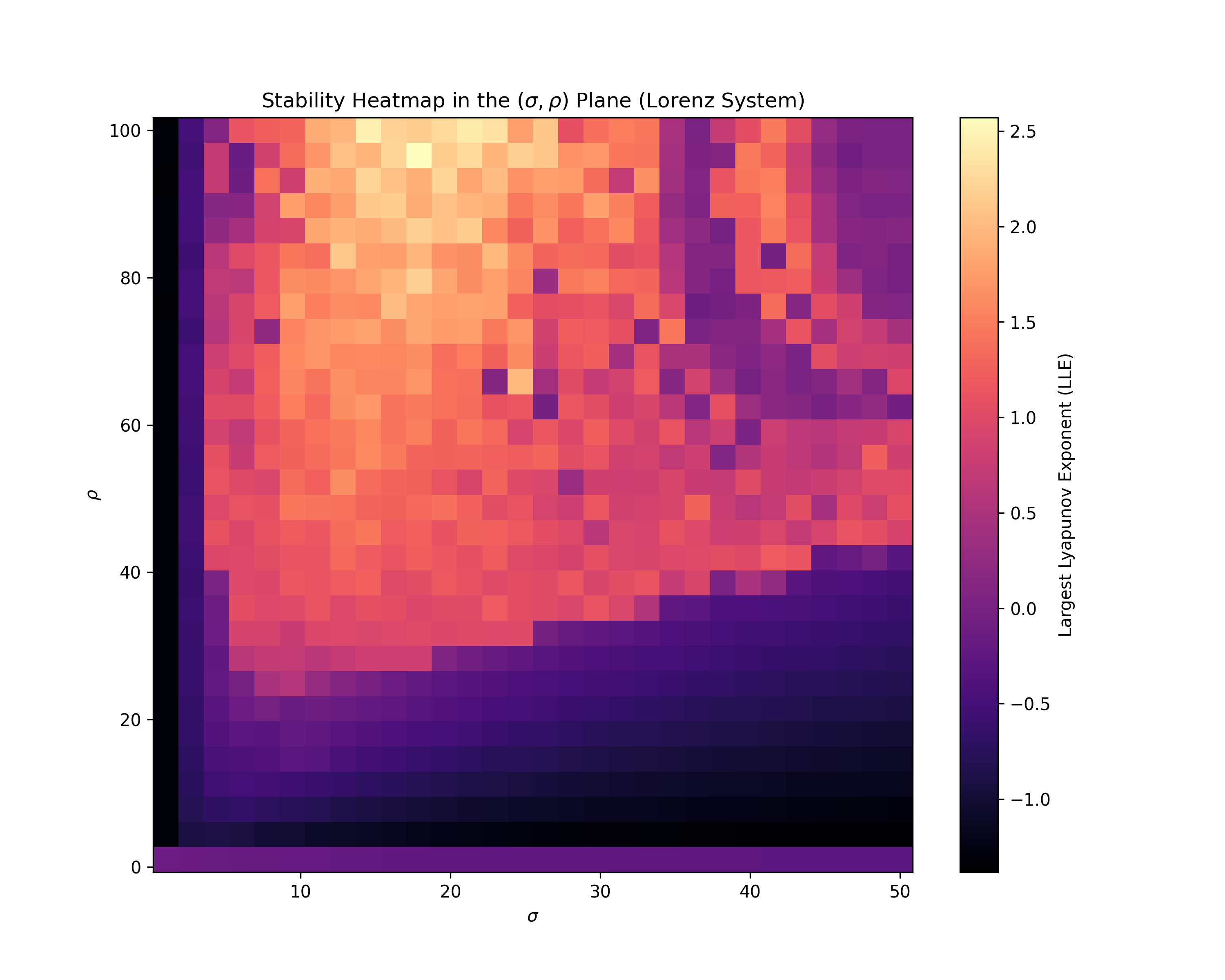
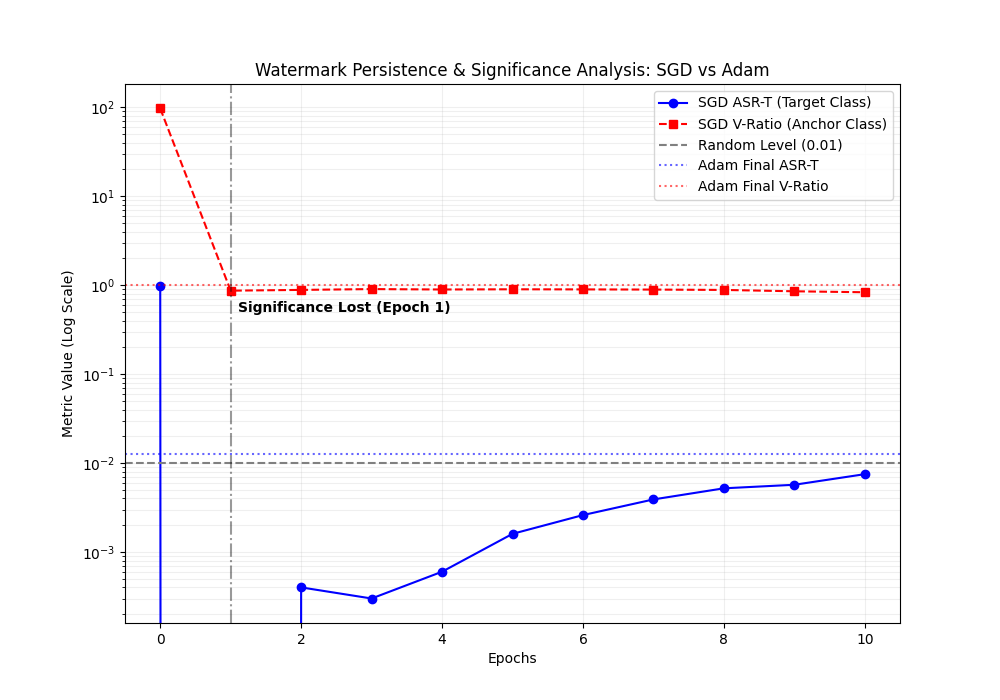
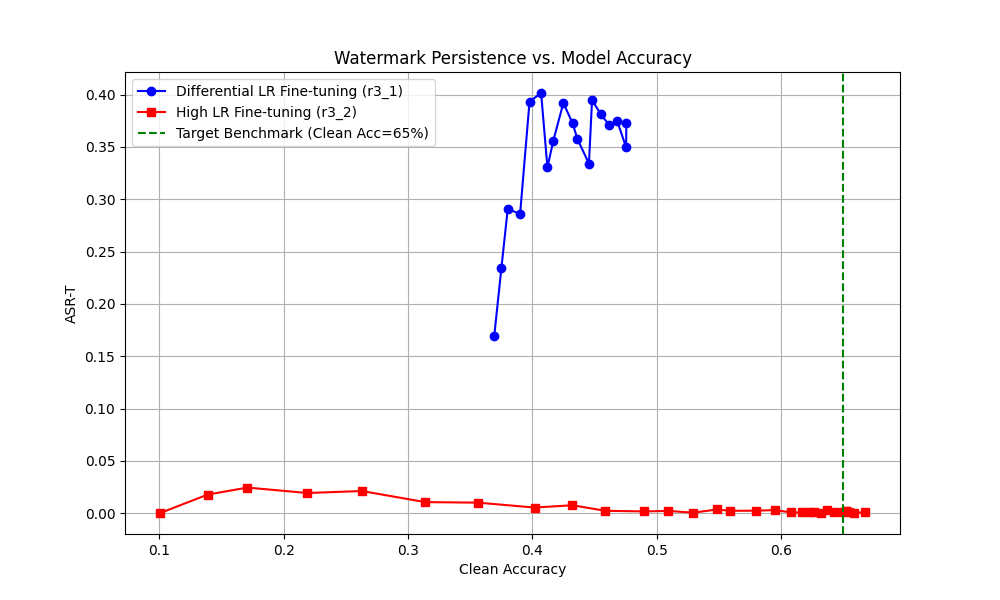
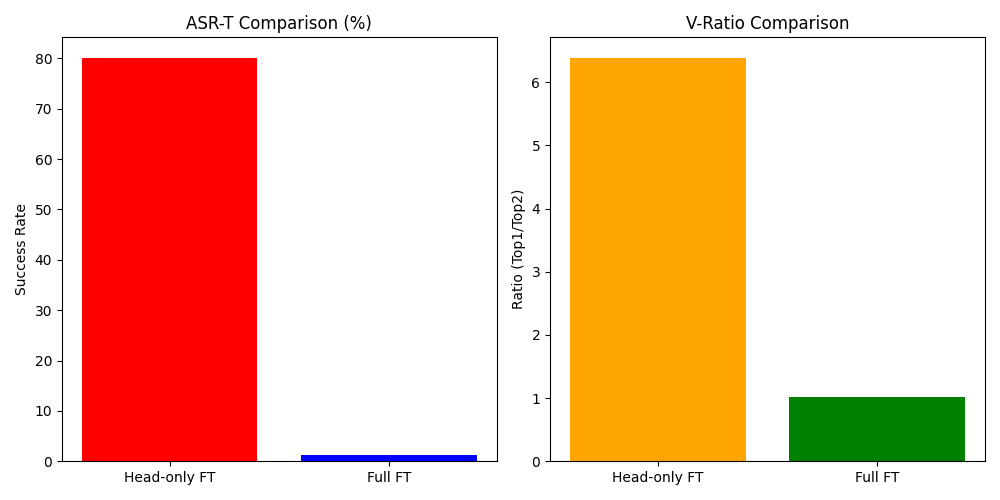
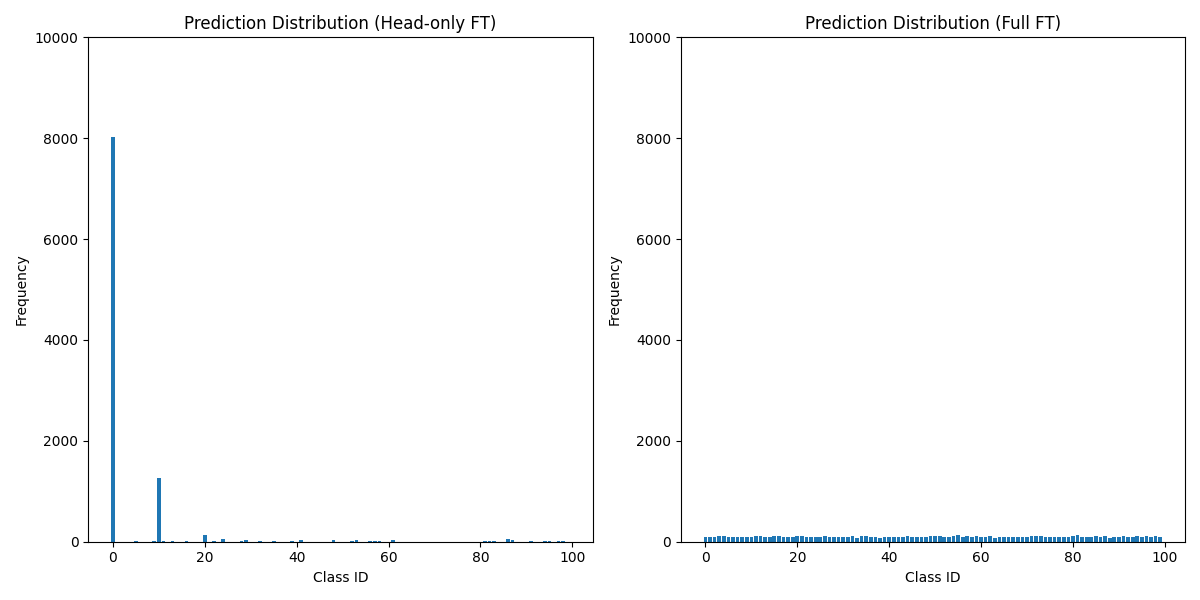
Does legitimate transfer learning weaken backdoor watermarks?
An empirical question: does legitimate fine-tuning erase a BadNets-style watermark? MAARS poisons a CIFAR-10 source, fine-tunes to CIFAR-100 under Head-only vs Full FT, and delivers the comparative figures that land in the paper.
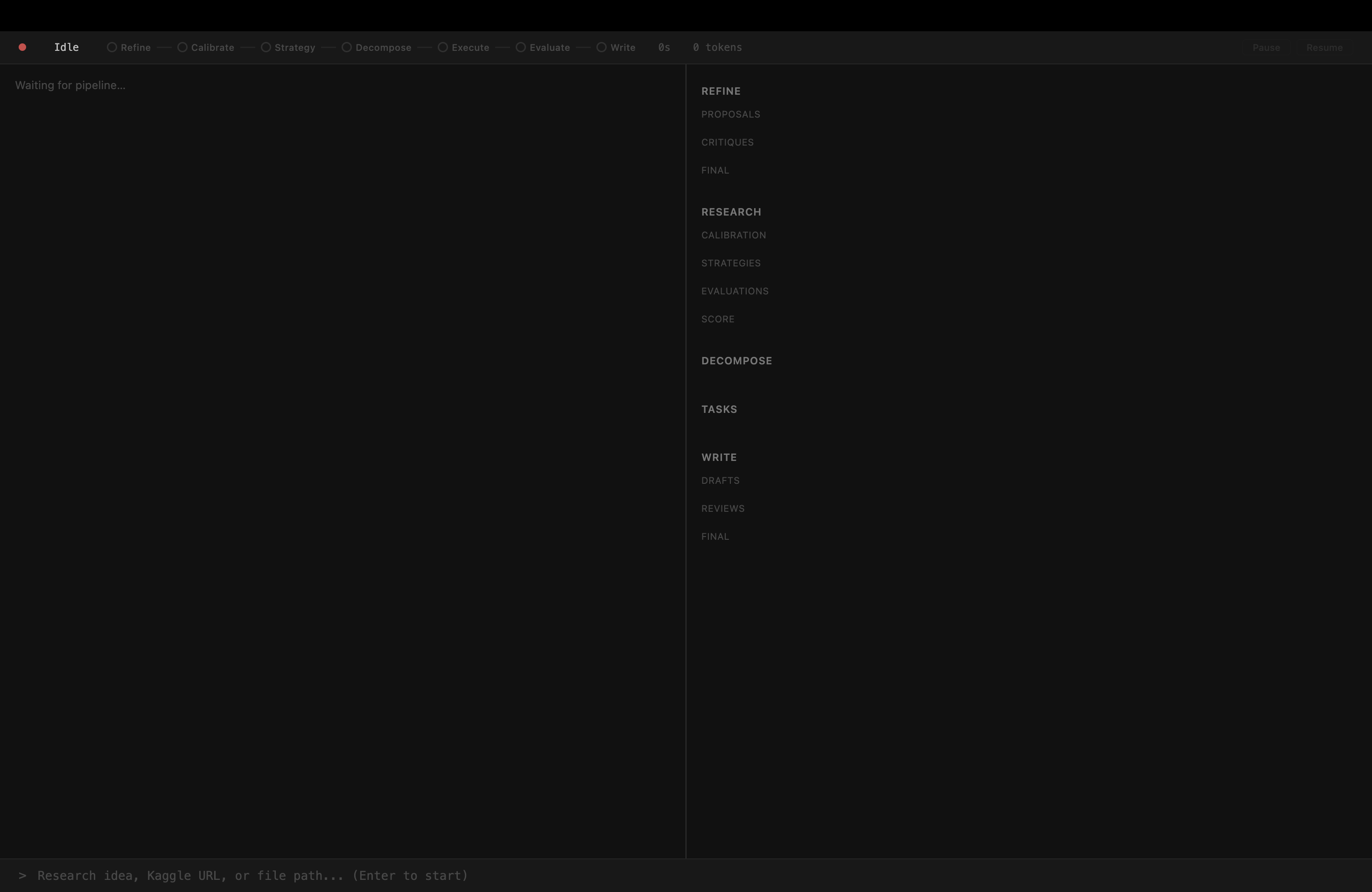
A window into the loop.
The left panel streams what every agent is thinking. The right panel is a live dashboard that reads canonical state from the session DB — proposals, plan trees, drafts, reviews.
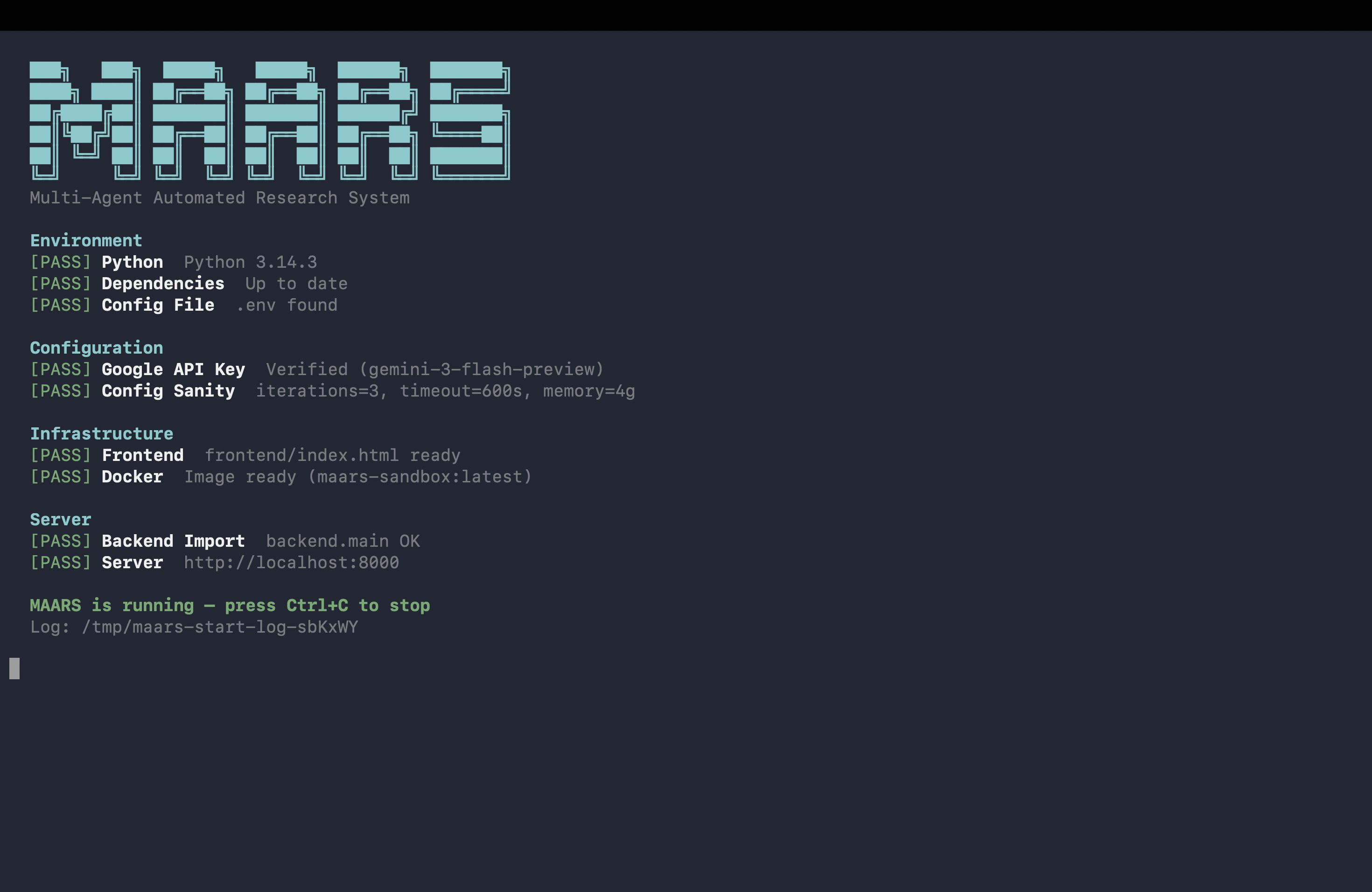
Run it locally.
One command to boot.
Requirements: Python 3.10+, Docker running, a Gemini API key.
# clone & run
git clone https://github.com/dozybot001/MAARS.git
cd MAARS
bash start.shOn first boot start.sh creates a venv, installs deps, scaffolds .env from the example, builds the sandbox image, and serves on localhost:8000. GPU is auto-detected.
Drop in an idea ›
Paste a research idea, a path to a UTF-8 text/markdown file, or a Kaggle competition URL. Kaggle mode auto-extracts the competition ID, downloads data, and skips Refine.
Tune per stage ›
Set MAARS_REFINE_MODEL, MAARS_RESEARCH_MODEL, etc. to override the default Gemini model per stage.
GPU passthrough ›
Install the NVIDIA Container Toolkit, set MAARS_DOCKER_SANDBOX_GPU=true, and the sandbox gets --gpus all for PyTorch training.
Read the design docs.
System boundaries, stage contracts, data flow, storage layout.
IterationState, reviewer contract, and Write-specific polish behavior.
Outer loop, task DAG, execution cycle, runtime guards, outputs.
Tool families, capability profile, scoping, and sandbox semantics.
Bring an idea.
Walk away with a paper.
MAARS is MIT-licensed, self-hostable, and reproducible by construction. Fork it, run it, break it.